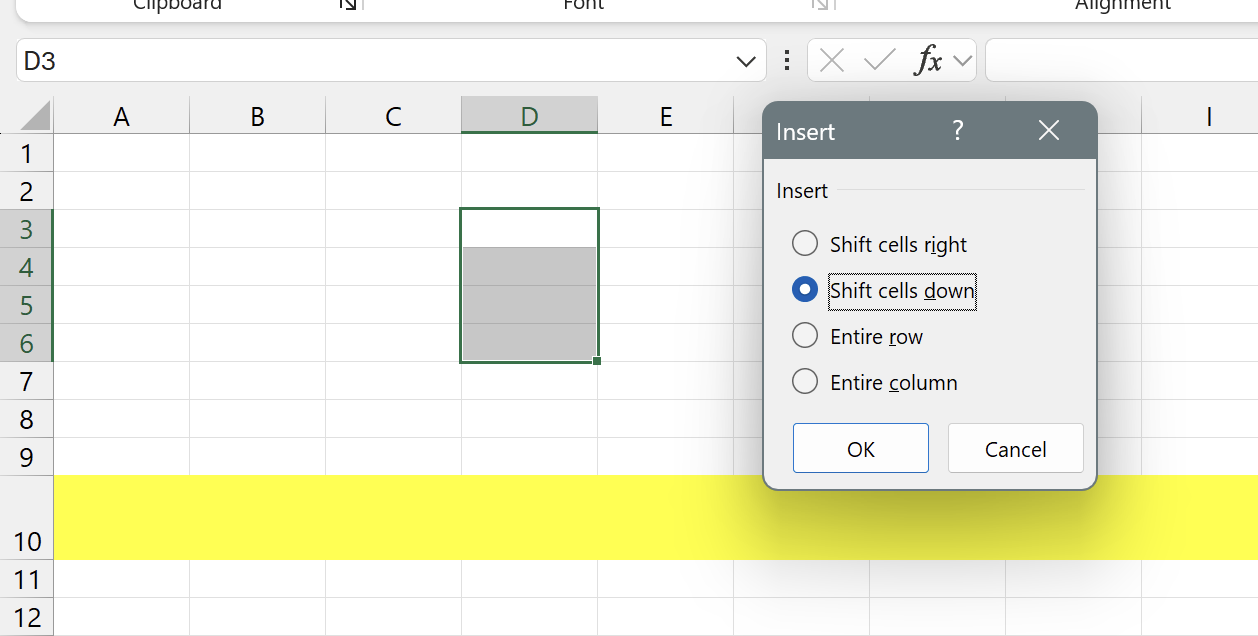
A master table (DummyMaster in the demo a virtual 1 row only table)
Two (potentially) different sized details next to each other (DetailLeft and DetailRight) within that master.
Below a footer is placed to test.
The master expands as expected keeping the footer intact.
However grouped regions and hidden rows below the master are not shiftet alongside.
I'd have expected them to stay consistently to the footer.
Sadly this is a known limitation of this approach, and there is not much that can be done to avoid it. It happens whenever you insert a range of cells instead of full columns.
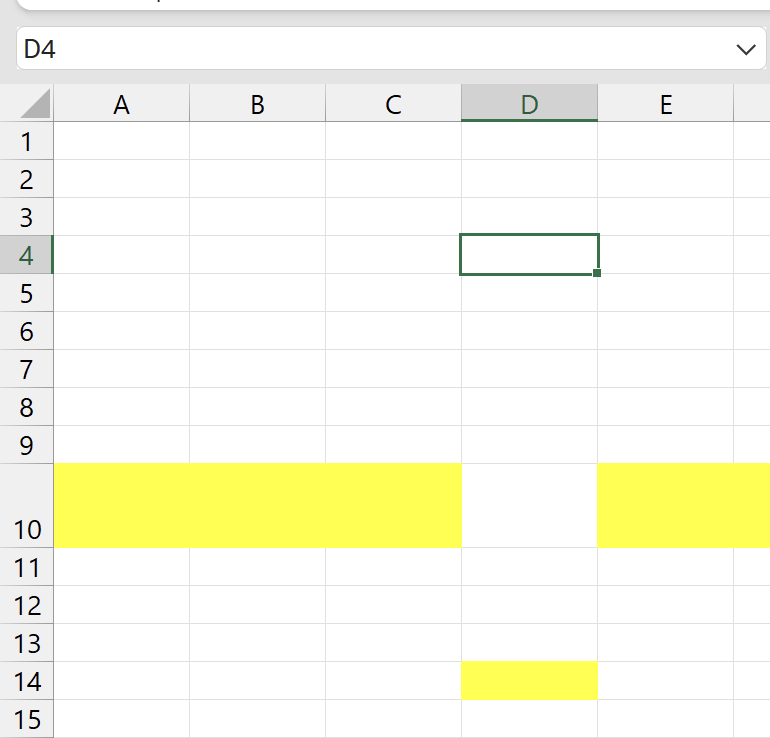
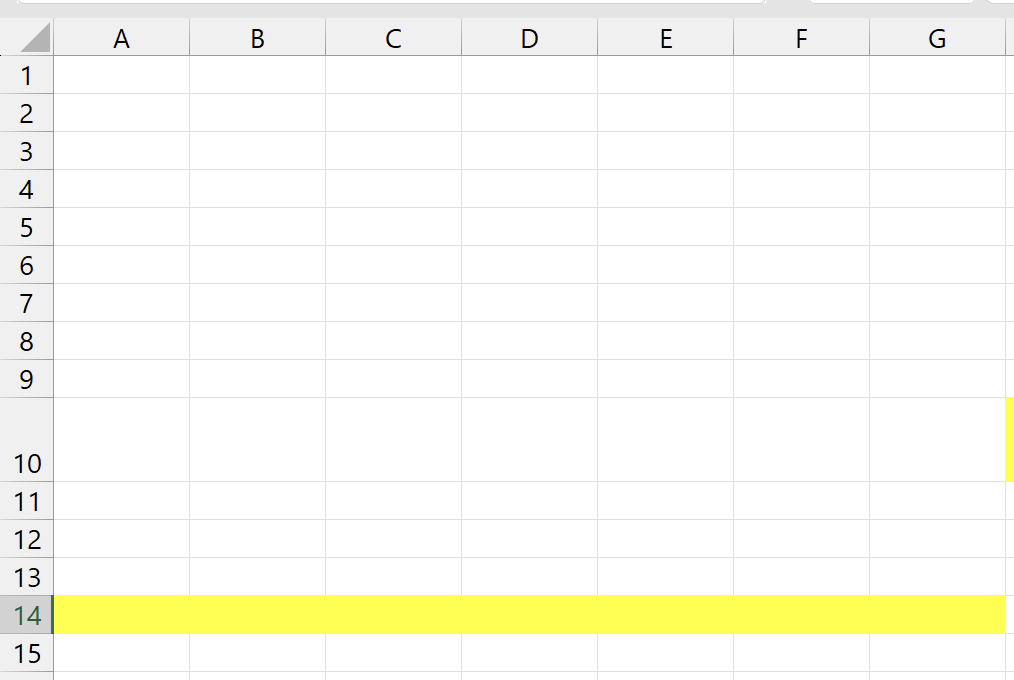
Note that row 10 is still taller, but row 14 is not. In an ideal world, cell D14 would be taller, and D10 would not, but that's not possible with a grid like the one in Excel. You can have either the full row taller or not, but not one cell of the row taller.
When FlexCel balances the bands, it will now insert cells in the rest of the columns so the row is moved down:
The yellow row will go down, but the row 10 will still be bigger, not row 14. This is because every time we insert cells, we aren't moving the full row, so the row doesn't move. We end up moving all the cells down, but the row didn't move. Something similar happens with merged cells: if when you insert some cells down you break a merged cell, and then insert cells to move the rest of the merged cell down, the cell won't remerge after it is moved.
The way to avoid this kind of stuff is to insert full rows, not parts of the rows. The workaround here is to join DetailLeft and DetailRight into one single dataset (you can use FlexCel's join or just do it in SQL: Join and Union (Delphi) | FlexCel Studio for VCL and FireMonkey documentation )
Then you just use a single __detail__ range that will move the full row down, and avoid breaking stuff when inserting only parts of the row
Thanks for the reply! Whilst JOIN works around the problem it introduced another bug (or limitation as well?).
When using tables directly as source, it works perfectly. However I'm defined them as virtual tables a filter in the config sheet which breaks.
In the example you can see that filtering alone works (the bottom approach using VLeft and VRight)
But JOINing VLeft + VRight produces wrong results (the middle example)
Hi,
Sorry, but it looks like the file test.xlsx wasn't included in the zip. I have the older test.xlsx from your first post but that doesn't include the join the config sheet. Can you reattach test.xlsx? Thanks!
Thanks for the file.
This is indeed a different limitation... but I'll see if it can be fixed
The issue in this file is not with the filtering, but with the fact that you are using the same dataset (DetailCombo) for both sides of the join. FlexCel does a big effort into not copying the full data every time you create a new dataset, so VLeft and VRight are sharing the same data (DetailCombo) and what is more important, the same cursor. (that is, when you move a record in VLeft, you are moving it in DetailCombo actually, and so are moving it in VRight which also has DetailCombo as datastore).
If you defined them as different backends:
Where DetailCombo2 is a TDataSet with the same data as DetailCombo, it would work as expected (I confirmed it here just in case). Also if those were TList<> it should work fine, as there is no cursor to be moved. The cursor position in a TDataSet causes a lot of issues, and in a lot of places FlexCel is moving it back and forward to avoid issues like this one, but in this particular case, JOIN just assumes the cursors for their 2 datasets are independent, and so it is not bothering to move it back every time the other branch is moved.
I think this could be fixed just by making JOIN aware that their 2 joined datasets can be in fact the same one under the hood, but I will check it now. I will confirm in a different post if it is feasible or not, without making slower the most common case (Joined datasets are independent)