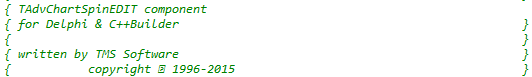I’m writing to ask whether future releases of your VCL components (e.g. TAdvMemo, TAdvSQLMemoStyler) could be delivered with their .pas source files saved in UTF-8 encoding (or include a {$CODEPAGE UTF8} directive).
Background:
I develop in Central European Latin-2 (Central Windows Latin 2) and also work with UTF-8 projects.
Your current source in Western Latin 1 makes accented characters (á, š, č, etc.) render incorrectly or appear as �.
Manually converting or patching each new release is error-prone and time-consuming.
Benefit:
Providing UTF-8–encoded sources (or using {$CODEPAGE UTF8} at the top of each unit) would eliminate character corruption, simplify upgrades, and better support international users.
Thank you for considering this enhancement!
Best regards,
Miroslav Baláž
Given this would break backwards compatibility with old Delphi versions, like Delphi 7, it is not something light to consider. Moreover, if you keep your own Latin-2 code outside our TMS VCL UI Pack source files but in your own UTF8 files, this should not matter. Did you try this approach?
This probably won't have a simple solution.
Latin-X is a problem for various reasons: Among other things, I'm currently making an archive of Delphi files with advanced SQL filtering in a SQLite database. Extremely efficient and flexible file search compared to Windows Explorer.
Delphi 7 doesn't know UTF8? I forgot. It was my favorite tool. I'm currently using Delphi Athens
I don't know a solution at the moment.
Even my own old code in Latin-2 encoding took me a lot of time. Directly in my own Delphi projects.
My Windows system locale (under Settings → Region → Administrative) has been set to “Beta: Use Unicode UTF-8 for worldwide language support” for several years now. I have very good reasons for this: my entire home network of PCs is configured the same way, and I regularly communicate with my children abroad, who live in both Latin-1 and Latin-2 regions. UTF-8 encoding is crucial for me.
As a result, Windows no longer uses a legacy “ANSI” code page (e.g. 1250/1252) and treats UTF-8 as the default ANSI code page. In Delphi, this causes most Latin-1 and Latin-2 characters to render as “�”. That symbol is the Unicode REPLACEMENT CHARACTER (U+FFFD). It marks any byte sequence that cannot be decoded into a valid Unicode character.
Here’s an example from the file opened in Delphi “AdvChartSpin.pas”:
{ TAdvChartSpinEDIT component }
{ for Delphi & C++Builder }
{ }
{ written by TMS Software }
{ copyright � 1996-2015 }
PS
On one machine I now have a clean, fully updated installation of TMS All Access (excluding TMS WEB Core). My new Delphi tool scanned 13 030 “*.pas” files in the TMS/Products folder. It found 2 892 files with a valid BOM (UTF-8 or UTF-16) and 107 files without a BOM that nevertheless contain ASCII bytes > 127—for example “çáÃé.” I deliberately skipped files that contain only “@µ�,” since there are so many of those. It’s clear that your installation already ships many files with a BOM!
I have explained why the situation is as-is today and I have suggested approaches for dealing with it, i.e. leave the TMS VCL UI Pack sources intact and deal with your special characters in application level source code.
I have also explained this is non-trivial & breaking for older Delphi version support to suddenly change this in our code.
On one machine I now have a clean, fully updated installation of TMS All Access (excluding TMS WEB Core). My new Delphi tool scanned 13 030 “*.pas” files in the TMS/Products folder. It found 2 892 files with a valid BOM (UTF-8 or UTF-16) and 107 files without a BOM that nevertheless contain ASCII bytes > 127—for example “çáÃé.” I deliberately skipped files that contain only “@µ�,” since there are so many of those. It’s clear that your installation already ships many files with a BOM!
Yes, I’ve read it. I’m offering you exactly what you requested at the start. However, many of your files use Latin-2 encoding. Please tell me which of those 107 I should compile in the way you need. Or, if you prefer, I can send you a list of those specific 107 files so you can choose which ones I should compile as example.
This category for your question suggests this concerns TMS VCL UI Pack. This has still the most broad Delphi IDE support, including non-unicode Delphi 7. Contrary to FNC or BIZ components for example that only support much newer and unicode enabled Delphi IDEs.
For the original demo TMS VCLUIPack project “..\tms\Products\tms.vcl.uipack\Demos\AdvSmoothComboBox\AdvSmoothComboBoxDemo.dproj”
I left all the files in their original form.
I’m sending the final screenshot of the sample solution.
I’ve created my own batch conversion of the TMS\Products source code from Latin-1 to UTF-8.
For the contents of the “..\TMS\Products” library, I assume that if a text file has no BOM, I use TEncoding.GetBufferEncoding to detect its encoding—and if that fails, I treat the file as being encoded in Latin-1.